
 Medir el rendimiento de tus
Medir el rendimiento de tus algoritmos
Como hacer benchmark de nuestros algoritmos en C o C++ en linux


El tiempo que tardan nuestro algoritmo en realizar una tarea depende enormemente de la cantidad de datos que les introducimos (algo que no podemos controlar) y el orden de complejidad del algoritmo (dependerá de nuestro algoritmo).
Existen varios métodos teóricos para hallar la complejidad de algoritmos, que no lo veremos en este artículo. Pero a manera de ejemplo el método de ordenamiento burbuja tiene una complejidad O(n^2), mientras que el algoritmo de ordenamiento Merge Sort tiene un orden de complejidad O(nlog(n)). Esto nos dice que en el peor de los casos el uso del método de la burbuja con una cantidad N de elementos realizará N*N Operaciones, lo cual es bastante malo ya que si le introduimos un millon de datos, tendríamos que realizar un billon de operaciones.
Estos métodos teóricos a veces son aburridores y complejos. La buena noticia es que podemos comparar un algoritmo usando el tiempo en el que el programa se está ejecutando en el procesador haciendo uso de la función getrusage en linux.
La idea es comenzar con tamaños de N pequeños e ir aumentando progresivamente.
La plantilla base es la siguiente:
#include<iostream>
#include<cmath>
#include<cstdlib>
#include <sys/time.h>
#include <sys/resource.h>
using namespace std;
int main(){
//Declaración de las variables que usaremos para comprobar el rendimiento
struct rusage usage;
struct timeval start, end;
double startsec,endsec;
//Hallamos el tiempo transcurrido hasta el momento
getrusage(RUSAGE_SELF, &usage);
start = usage.ru_utime;
startsec = start.tv_sec + (double)start.tv_usec/1000000;
cout<<"Inicio:"<<startsec<<"\n";
///////////////////////////////////
//Aquí colocamos las órdenes que queremos procesar
//////////////////////////////////
//Hallamos el tiempo que ha transcurrido y lo restamos con el tiempo inicial.
getrusage(RUSAGE_SELF, &usage);
end = usage.ru_utime;
endsec = end.tv_sec + (double)end.tv_usec/1000000;
cout<<"Fin:"<<endsec<<" Diferencia: "<<endsec-startsec<<"\n";
}
Ejemplo: Algoritmo de Merge Sort
#include<iostream>
#include<cmath>
#include<cstdlib>
#include <sys/time.h>
#include <sys/resource.h>
using namespace std;
void merge(int * inicio, int med,int fin){
int * auxiliar = new int[fin];
int k = 0, i = 0, j = med;
while(k < fin){
if(inicio[i] < inicio[j])
auxiliar[k] = inicio[i++];
else if (inicio[i] > inicio[j])
auxiliar[k] = inicio[j++];
else if(i >= med)
auxiliar[k] = inicio[j++];
else
auxiliar[k] = inicio[i++];
k++;
}
copy(auxiliar, auxiliar+fin, inicio);
delete(auxiliar);
}
void mergesort(int * array,int size){
if(size <= 1) return;
int med = floor(size/2);
mergesort(array,med);
mergesort(array+med,size-med);
merge(array,med,size);
}
int main(){
struct rusage usage;
struct timeval start, end;
double startsec,endsec;
int size = 10000000;
int * hola = new int[size] ;
srand(0);
for(int i = 0; i < size; i++)
hola[i] = rand();
getrusage(RUSAGE_SELF, &usage);
start = usage.ru_utime;
startsec = start.tv_sec + (double)start.tv_usec/1000000;
cout<<"Inicio:"<<startsec<<"\n";
mergesort(hola,size);
getrusage(RUSAGE_SELF, &usage);
end = usage.ru_utime;
endsec = end.tv_sec + (double)end.tv_usec/1000000;
cout<<"Fin:"<<endsec<<" Diferencia: "<<endsec-startsec<<"\n";
}
Como referencia, el algoritmo de la burbuja ordenar 1000000 de datos tardó 30 minutos en terminar, usando el método de merge sort el ordenamiento demoró 3 segundos.
 The Samizdat incident
The Samizdat incidentAunque el título facilmente podría ser el nombre de un capítulo de The Big Bang Theory, no es así. Ya hablamos en el artículo la historia de linux, el debate que se g
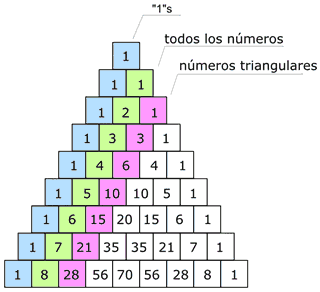 Triangulo de pascal en C++
Triangulo de pascal en C++ Como se identifican los procesos en un sistema operativo
Como se identifican los procesos en un sistema operativo